I stumbled across an interesting paper called The road to SDN: an intellectual history of programmable networks (ACM DL link) this morning. It’s good to place current trends in historical context especially while keeping RFC 1925 Rule 11 in mind.
The concept of active networking is particularly intriguing to me. Could eBPF be the instruction set for a revival in this area? This may not make sense on a per-packet basis but perhaps for larger PDUs/messages?

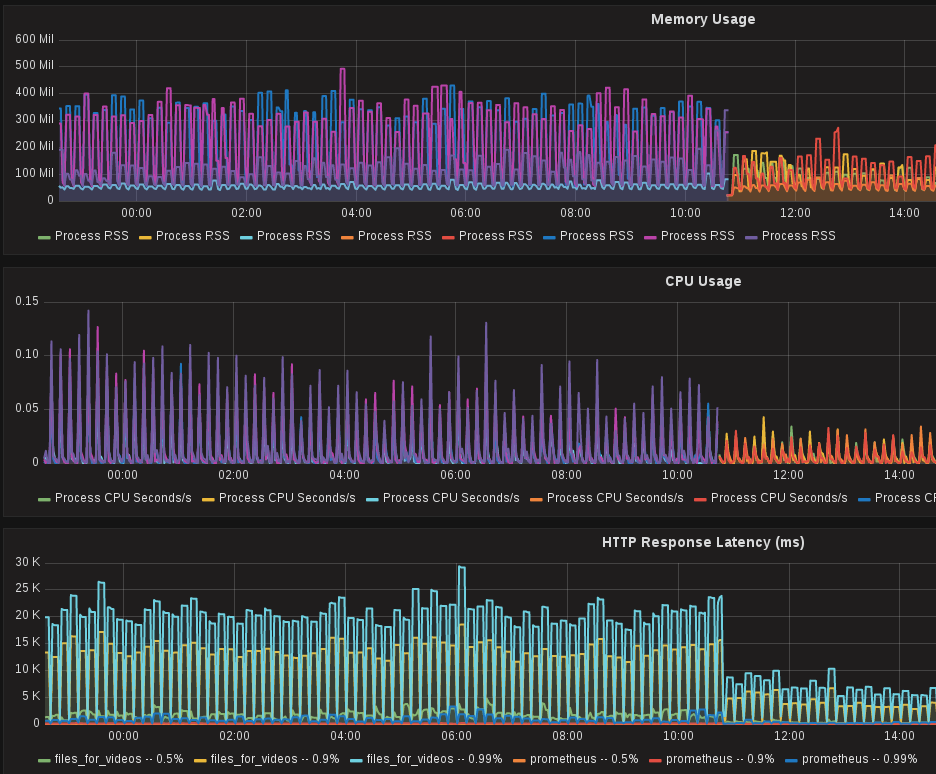

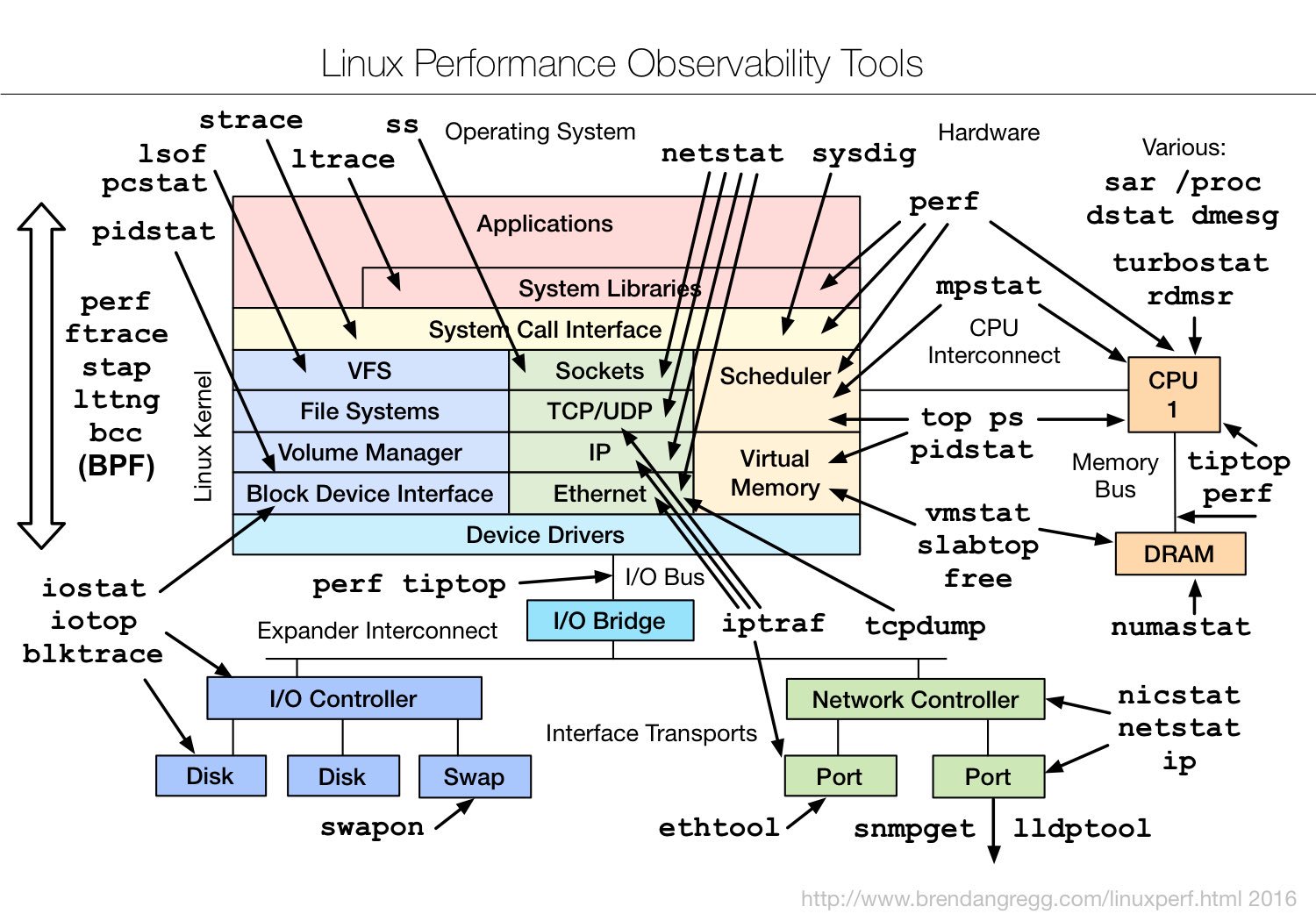
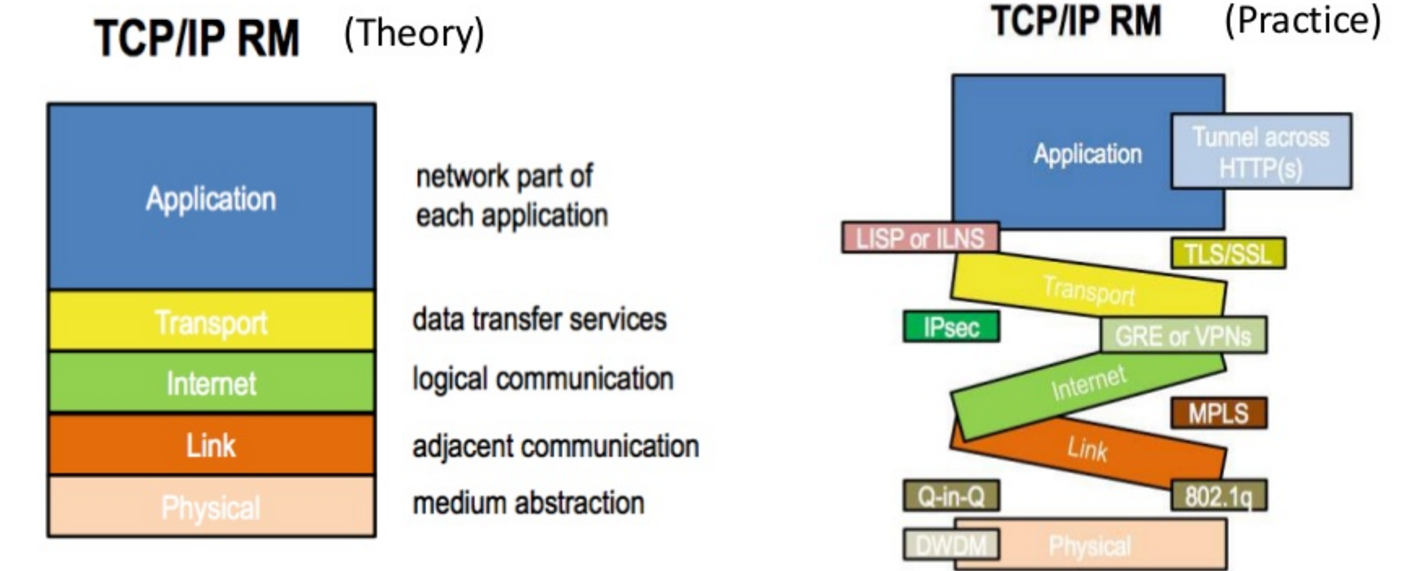
{kind=link}