

Linux Journal has an article in the January 2005 issue that introduces a doubly linked list that is designed for memory efficiency.
Typically elements in doubly linked list implementations consist of a pointer to the data, a pointer to the next node and a pointer to the previous node in the list.


The more memory efficient implementation described in the article stores a single offset instead of the next and previous pointers.
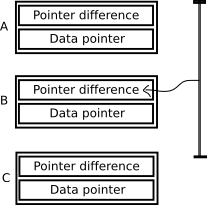
The pointer difference is calculated by taking the exclusive or (XOR) of the memory location of the previous and the next nodes. Like most linked list implementations a NULL pointer indicates a non-existent node. This is used at the beginning and end of the list. For the diagram above, the pointer differences would be calculated as follows:
A[Pointer difference] = NULL XOR B
B[Pointer difference] = A XOR C
C[Pointer difference] = B XOR NULL
One nice property of XOR is that it doesn’t matter what order the operation is applied. For example:
A XOR B = C
C XOR B = A
A XOR C = B
The memory efficient linked list uses this property of XOR for traversals. The trick is that any traversal operation requires both the address of current node and the address of either the preceding or following node.
Using the example figure above, calculating the address of the B node from A looks like:
B = NULL XOR A[Pointer difference]
What is really interesting is that traversing the list operates exactly the same in both directions. As shown below calculating the address of node A or C from B is simply depends on which direction the traversal is going.
A = C XOR B[Pointer difference]
C = A XOR B[Pointer difference]
The original article presents some time and space complexity results. I won’t bother repeating them here.